big data
US
・UK
A1 初級
n. (u.)不可算名詞ビッグデータ
Big data is revolutionizing the way companies understand their customers.
動画字幕
ビッグデータ vs ファストデータ:AI戦略を最適化 (Big Data vs Fast Data: Optimize Your AI Strategy)

- And if you don't understand the difference between big data and fast data, you might be building your AI strategy on the wrong foundation.
また、ビッグデータとファストデータの違いを理解していなければ、間違った土台の上にAI戦略を構築することになるかもしれない。
- And if you don't understand the difference between Big Data and Fast Data, you might be building your AI strategy on the wrong foundation.
また、ビッグデータとファストデータの違いを理解していなければ、間違った土台の上にAI戦略を構築することになるかもしれない。
なぜこのチームは10万のアジアゲノムをシーケンスしようとしているのか (Why this team is trying to sequence 100,000 Asian genomes)

- Without the technology we cannot handle this big data.
テクノロジーがなければ、このビッグデータを扱うことはできない。
- Without the technology, we cannot handle this big data.
ゲノム・アジア100kの目標達成には、まだ道半ばである。
40年間、危ない橋を渡り続けてきた ("I've Been Skating On Thin Ice For 40 Years")

- We developed the strategy for Libratus. Libratus is the first poker AI run on Bridges, which is the newest supercomputer at the Pittsburgh Supercomputing Center. Bridges is the largest system in the world that converges high-performance computing with artificial intelligence and big data. I'm Nick Nystrom. I'm interim director at the Pittsburgh Supercomputing
Libratus の戦略を開発しました。Libratusは、ピッツバーグ・スーパーコンピューティング・センターの最新スーパーコンピューターであるBridges上で実行される最初のポーカーAIである。ブリッジズはハイパフォーマンスコンピューティングと人工知能、ビッグデータを融合させた世界最大のシステムです。私はニック・ナイストロム。ピッツバーグ・スーパーコンピューティング・センターの暫定ディレクターです。
- Bridges is the largest system in the world that converges high-performance computing with artificial intelligence and big data.
イングリッシュポッドキャスト | 人工知能があなたの人生を永遠に変える | 英語学習ポッドキャスト (English Podcast | Artificial Intelligence Will Change Your LIFE Forever | Learn English Podcast)

- Next word is big data.
これは、人間の脳の構造と機能を模倣して、パターンを認識し、決定を下すAIの一種を意味します。
- Example: AI uses big data to predict consumer behavior and recommend products in online stores.
これは、コンピューターが人間の言語を理解し、解釈し、応答するのを助けるAIの分野を意味します。
ラーニング・アナリティクス・フューチャーズ:ブライアン・アレクサンダー – フルインタビュー (Learning Analytics Futures: Bryan Alexander – Full Interview)

- and some of them include learning analytics, everything from big data, uh, to AI.
ジョージタウン大学で教鞭をとり、様々な問題に首を突っ込んでいます。
- And some of them include learning analytics, everything from big data to AI.
それらの中には、ビッグデータからAIに至るまでの学習分析も含まれています。
コストコの物語 || ポッドキャストで英語を学ぼう || レベル2 || 英語のスピーキング力向上 ✅ (The Costco Story || Learn English With Podcast || Level 2 || Improve Your English Fluency ✅)

- Big data and personal ads were now guiding consumer behavior.
共同創業者でありCEOのジム・シネガル氏が退任することになったのです。
- Big data and personal ads were now guiding consumer behavior.
企業はクリックのすべて、習慣のすべてを追跡しました。
AIの利用は環境に影響を与えるのか? - BBCワールドサービス (Does using AI impact the environment? - BBC World Service)

- And I was reading that the International Energy Agency has estimated that the electricity consumption of the big data centres will actually double between now and 2030.
もう少し話を戻しますが、そもそもAIが使用するエネルギーはどこから来ているかご存知ですか?
- And I was reading that the International Energy Agency has estimated that the electricity consumption of the big data centers will actually double between now and 2030.
そして、国際エネルギー機関の推計によると、大規模データセンターの電力消費量は2030年までに倍増すると読んだことがあります。
NVIDIAネットワーキング:データセンター設計の考慮事項 (NVIDIA Networking: Data Center Design Considerations)
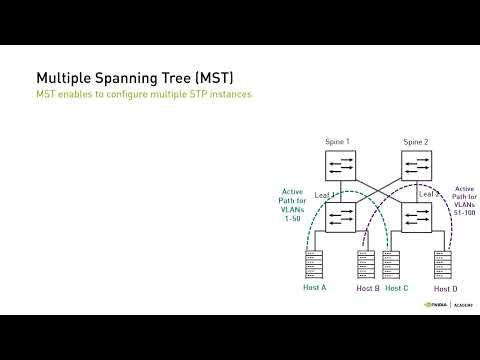
- Cloud computing, virtualization, Big data and related trends have come together to transform data centers.
クラウドコンピューティング、仮想化、ビッグデータ、および関連するトレンドが組み合わさって、データセンターを変革しました。
- Cloud computing, virtualization, big data, and related trends have come together to transform data centers.
リーフスパインアーキテクチャは、リーフ層とスパイン層で構成される2層のフルメッシュトポロジーです。
私たちの暮らしを変えたテクノロジー革命、そして最大の変化はこれからやってくる (The Tech Revolution That Changed How We Live and Why The Biggest Change is Yet to Come)

- I think if you can take the very complex cases of disease or drugs and forget these big data centers, connect that with a quantum computer, with the knowledge within the AI systems and the data structures and the volume of that data and all those case histories and things that could be significant, that could be a significant breakthrough.
病気や薬の非常に複雑なケースを取り上げ、これらの大規模なデータセンターを無視し、それを量子コンピューターと、AIシステム内の知識、データ構造、そのデータの量、そしてそれらすべての症例履歴や重要なものと結びつけることができれば、それは大きな進歩につながるでしょう。
- I think if you can take very complex cases of disease or drugs and forget these big data centers, connect that with a quantum computer, with the knowledge within the AI systems and the data structures and the volume of that data and all those case histories and things, that could be significant.
量子マシンは、非常に得意なことを行い、それを返します。
Databricks Lakehouse Platform入門 (Intro to Databricks Lakehouse Platform)

- You'll also learn how to define the Databricks Lakehouse platform, give examples of how to solve big data challenges, and
また、Databricks Lakehouse Platformの定義方法、ビッグデータ課題の解決例、
- In this video, you'll learn about Databricks and the Databricks Lakehouse Platform, you'll also learn how to define the Databricks Lakehouse Platform, give examples of how to solve big data challenges,
また、Databricks Lakehouse Platformの定義方法、ビッグデータ課題の解決例、