
browser
US /ˈbraʊzɚ/
UK /ˈbraʊzə(r)/
- n.ブラウザ
B1 中級TOEICもっと見るbunch
US /bʌntʃ/
UK /bʌntʃ/
- n. (c./u.)集まり;仲間
- v.t.まとまる
- v.t./i.束ねられる
B1 中級もっと見るcode
US /kod/
UK /kəʊd/
- v.t.コード化する;暗号化する;コーディングする : プログラムする
- n.コード;行動規範;暗号;コーディング;法典;遺伝コード
A2 初級もっと見るcollect
US /kəˈlɛkt/
UK /kəˈlekt/
- adv.(電話が)料金受信人払いで
- v.t.寄付を募る;集める : まとめる;(趣味として)~を収集する;収集する;(あちこちから)集める;(賞 : 賞金などを)受け取る;心を落ち着ける:気を取り直す
- adj.着払い
- n.集祷文
A2 初級もっと見るcollection
US /kəˈlɛkʃən/
UK /kəˈlekʃn/
- n. (c./u.)徴収;収集物;収集;取り立て;コレクション;データ収集;作品集;献金;美術コレクション
A2 初級もっと見るcontent
US /ˈkɑnˌtɛnt/
UK /'kɒntent/
- adj.満足している;満足した
- n. (c./u.)内容;主題;コンテンツ;満足;コンテンツ;含有量
- v.t.満足させる
- v.i.同意する
A2 初級もっと見るcorpus
US /ˈkɔ:rpəs/
UK /ˈkɔ:pəs/
- n.資料の集成 : 集成 : 全集
B2 中上級もっと見るcrawl
US /krɔl/
UK /krɔ:l/
- v.t./i.ゆっくり進行する;はう : はいはいする;はう
- n. (u.)ゆっくり進行すること
- n.クロール(水泳)
B1 中級もっと見るdepend
US /dɪˈpend/
UK /dɪˈpend/
- v.t./i.決まる;頼る;次第である
B1 中級TOEICもっと見るdepending on
US
UK
- phr. v.頼る;〜によって
- prep.〜によって;〜を頼りにする
- ger.頼ること
- v.t./i.頼っている;〜によって
A2 初級もっと見るdo in
US
UK
- phr. v.疲れさせる;破壊する;殺す
A1 初級もっと見るengine
US /ˈɛndʒɪn/
UK /'endʒɪn/
- n. (c./u.)エンジン;機関;エンジン;消防車;原動力
A2 初級TOEICもっと見るeventually
US /ɪˈvɛntʃuəli/
UK /ɪˈventʃuəli/
- adv.最終的には;いつか
A2 初級もっと見るexciting
US /ɪkˈsaɪtɪŋ/
UK /ɪkˈsaɪtɪŋ/
- v.t.興奮させる、活発にさせる;興奮させる
- adj.わくわくさせる;わくわくする;刺激する
A2 初級もっと見るextract
US /ɪkˈstrækt/
UK /'ekstrækt/
- n. (c./u.)エッセンス;抜粋;抽出物
- v.t.エキスを抽出する;聞きだす;引き出す;抜き出す
B1 中級TOEICもっと見るfigure out
US /ˈfɪɡjɚ aʊt/
UK /ˈfiɡə aut/
- phr. v.(人の態度 : 行動を)理解する;解決策を考え出す;解明する;考え出す;計算する
- v.t./i.理解する;解明する;見つけ出す;計算する
- phr.v.理解する、解決する
A1 初級もっと見るfirst three
US
UK
- det.最初の3つ
- adj.上位3名
A1 初級もっと見るfrequently
US /ˈfrikwəntlɪ/
UK /ˈfri:kwəntli/
- adv.頻繁に;度々;一般的に
A2 初級TOEICもっと見るfunctional
US /ˈfʌŋkʃənəl/
UK /ˈfʌŋkʃənl/
- adj.機能的な;機能している;機能的な(医学);機能的な (建築)
- n.汎関数 (数学)
A2 初級もっと見るgo beyond
US /ɡo biˈɑnd/
UK /ɡəu biˈjɔnd/
- phr. v.(計画 : 予想などを)超える
A1 初級もっと見るgoal
US /ɡol/
UK /ɡəʊl/
- n. (c./u.)目的 : 目標;(スポーツの)ゴール;得点を入れること
A2 初級TOEICもっと見るkeyword
US /ˈki:wɜ:rd/
UK /ˈki:wɜ:d/
- n.キーワード
B1 中級もっと見るlink
US /lɪŋk/
UK /lɪŋk/
- n. (c./u.)(鎖のひとつの)輪 : 環;つながり;(インターネットの)リンク
- v.t.つなぐ : 連結する;関連付ける
A2 初級TOEICもっと見るlook at
US /lʊk æt/
UK /luk æt/
- phr. v.見る;注目する;見る;調べる
A1 初級もっと見るnecessarily
US /ˌnɛsɪˈsɛrəli, -ˈsɛr-/
UK /ˌnesəˈserəli/
- adv.必ず : 必然的に
A2 初級TOEICもっと見るpointer
US /ˈpɔɪntɚ/
UK /'pɔɪntə(r)/
- n.助言 : 忠告;指示棒 : ポインター
A2 初級TOEICもっと見るpowerful
US /ˈpaʊəfəl/
UK /ˈpauəful/
- adj.強力な : 効力のある;力強い : エネルギーのある
A2 初級TOEICもっと見るprint out
US /prɪnt aʊt/
UK /print aut/
- phr. v.印刷する
A1 初級もっと見るrank
US /ræŋk/
UK /ræŋk/
- v.t.順位付けする;順位付け;並べる
- n.(特定の人の)集団 : 部類;ランキング : 順位付け;タクシー乗り場;列
- adj.完全な;制御できない;悪臭の
B1 中級TOEICもっと見るremain
US /rɪˈmen/
UK /rɪˈmeɪn/
- v.i.残る;居残る;存続する
A2 初級TOEICもっと見るrequest
US /rɪˈkwɛst/
UK /rɪ'kwest/
- v.t.(正式 : 丁寧に)依頼する
- n.要請;リクエスト;リクエスト
A2 初級TOEICもっと見るrespond
US /rɪˈspɑnd/
UK /rɪ'spɒnd/
- v.t./i.返事する;反応する;反応する;答弁する
A2 初級TOEICもっと見るresponse
US /rɪˈspɑns/
UK /riˈspɔns/
- n.返答;反応;呼応;(医療)反応;(コンピューター)応答
A2 初級TOEICもっと見るscience
US /ˈsaɪəns/
UK /'saɪəns/
- n. (u.)科学
A2 初級TOEICもっと見るsearch
US /sɜ:rtʃ/
UK /sɜ:tʃ/
- v.t.(持ち物 : 体を)検査する;探す;探す
- n. (c./u.)身体検査;探求;(徹底した)
A2 初級TOEICもっと見るsearch for
US /sɚtʃ fɔr/
UK /sə:tʃ fɔ:/
- phr. v.探す
B1 中級もっと見るsee in
US /si ɪn/
UK /si: in/
- phr. v.見送る
A1 初級もっと見るseed
US /sid/
UK /si:d/
- n. (c./u.)子供 : 子孫;種;案;シード戦
- v.i.種ができる : 種子ができる : 結実する
- v.t.種を取り出す;案をうえつける;種を植える
B1 中級もっと見るshow up
US /ʃo ʌp/
UK /ʃəu ʌp/
- phr. v.(パーティーなど)に現れる : で姿を見かける;際立ってよい;あばく
A1 初級もっと見るsite
US /saɪt/
UK /saɪt/
- n. (c./u.)現場;場所 : 敷地 : 用地;場所;現場;ウェブサイト
- v.t.立地を決める : 位置する
A2 初級TOEICもっと見るsolve
US /sɑ:lv/
UK /sɒlv/
- v.t.解決する
A2 初級TOEICもっと見るstart out
US /stɑrt aʊt/
UK /stɑ:t aut/
- phr. v.始める;出発する
A1 初級もっと見るtake on
US /tek ɑn/
UK /teik ɔn/
- phr. v.(新しい性質 : 特徴を)獲得する;引き受ける;雇う;対戦する
A1 初級もっと見るthink of
US /θɪŋk ʌv/
UK /θiŋk ɔv/
- phr. v.~としてみなす;考える;想像する
- v.t./i.想像する
A1 初級もっと見るunderscore
US //ˌʌndərˈskɔr//
UK
- v.t.強調する;配樂
- n.アンダースコア;アンダースコア
C1 上級もっと見るunexpected
US /ˌʌnɪkˈspektɪd/
UK /ˌʌnɪkˈspektɪd/
- adj.予期しない
- n.不測の事態
B2 中上級もっと見るunit
US /ˈjunɪt/
UK /ˈju:nɪt/
- n. (c.)ひと部屋;(軍事)部隊;(教科書の)単元;単位;単品
B2 中上級TOEICもっと見るvehicle
US /ˈvi:hɪkl/
UK /ˈvi:əkl/
- n. (c./u.)乗り物;方法;媒体;表現手段;宇宙船
A2 初級TOEICもっと見る
Vocabulary
- figure out: (人の態度 : 行動を)理解する
- do in: 疲れさせる
- take on: (新しい性質 : 特徴を)獲得する
- start out: 始める
- first three: 最初の3つ
- think of: ~としてみなす
- see in: 見送る
- show up: (パーティーなど)に現れる : で姿を見かける
- depending on: 頼る
- go beyond: (計画 : 予想などを)超える
- print out: 印刷する
- look at: 見る
- search for: 探す
- page: ページ
- find: 気づく : 感じる
- lot: 運命
- start: 開始時刻 : 開始場所 : 開始
- learn: 学ぶ
- important: 地位の高い
- good: 適した
- exciting: 興奮させる、活発にさせる
- computer: コンピュータ
- small: 小さい
- class: 分類する
- write: 書く
- ask: 尋ねる
- go: 行く
- to: に
- web: 水かき
- engine: エンジン
- build: 体型
- collect: (電話が)料金受信人払いで
- follow: 後について行く
- goal: 目的 : 目標
- text: メールを作成
- list: 傾く : かしぐ
- pointer: 助言 : 忠告
- building: 築く
- print: 印刷する
- site: 現場
- wide: 広い
- science: 科学
- main: 主要な
- unit: ひと部屋
- search: (持ち物 : 体を)検査する
- link: (鎖のひとつの)輪 : 環
- figure: 出場する
- request: (正式 : 丁寧に)依頼する
- appear: 現れる
- content: 満足している
- frequently: 頻繁に
- vehicle: 乗り物
- remain: 残る
- collection: 徴収
- solve: 解決する
- depend: 決まる
- bunch: 集まり
- powerful: 強力な : 効力のある
- browser: ブラウザ
- extract: エッセンス
- seed: 子供 : 子孫
- response: 返答
- crawl: ゆっくり進行する
- programming: 人の行動をあらかじめ決める
- functional: 機能的な
- respond: 返事する
- code: コード化する
- necessarily: 必ず : 必然的に
- eventually: 最終的には
- rank: 順位付けする
- corpus: 資料の集成 : 集成 : 全集
- keyword: キーワード
- underscore: 強調する
- unexpected: 予期しない
- program: (人が)~するように方向づける
アプリで完全な体験を
いつでもどこでも学習、文章と使い方を詳しく解説
01:03
She took a brave step forward, leaving behind her comfort zone to chase her dreams.
単語・フレーズ
- brave
adj. 勇気のある
- comfort zone
phr. コンフォートゾーン
文の解説
a brave step は名詞句で、brave は形容詞として名詞 step を修飾し、「勇敢な一歩」を意味します。
forward は副詞として step を修飾し、「前へ」を意味します。
この句全体が目的語となり、took(動詞)の「何を」に答えています——彼女は勇敢な一歩を前へ踏み出した。
アプリで完全な体験を
いつでも単語を調べて、発音・品詞・使い方をマスター
brave
US/brev/
UK/breɪv/
adj.勇敢な
v.t.勇敢に立ち向かう
A2 初級
アプリで完全な体験を
いつでもどこでもスピーキング練習、即時に発音フィードバック
Try this speaking exercise.
この文を真似して練習してみましょう。
80
0
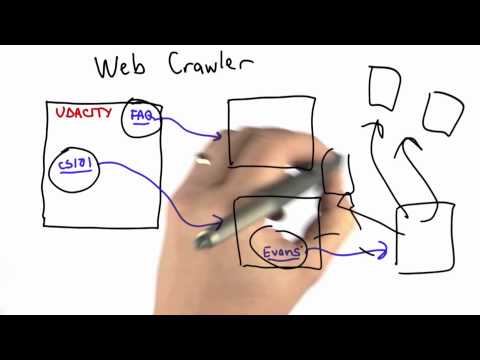
Chris Lyu が 2021 年 01 月 14 日 に投稿検索エンジンはどうやって情報を見つけているか、不思議に思ったことはありませんか?この動画では、Webクローラーの構築とリンク抽出の仕組みを解説します。情報検索の基本を学びたいCS学生にぴったりです!『corpus』や『indexing』といった重要な語彙も、インターネットの仕組みを実践的に学ぶ中で自然と身につくでしょう。
この動画をアプリで学ぼう!
VoiceTubeアプリ版なら、効果的な学習機能がもっと充実しています!