Vocabulary
- instead of: の代わりに
- going on: ~し続ける
- have to: する必要がある
- at a time: 一度に
- depending on: 頼る
- look at: 見る
- over time: 時が経つにつれて
- got to: 到着する
- in terms of: の面では
- just kind of: なんとなく
- in the way: 邪魔になって
- figure out: (人の態度 : 行動を)理解する
- regardless of: かかわらず
- set up: セットアップ
- look for: (いない人 : なくなった物を)探す
- fit into: 入る
- tag on: (何かを)追加する、付け加える
- based on: ~に基づいている
- rather than: どちらかといえば
- think about: 考慮する
- for instance: 例えば
- by default: デフォルトで
- in charge: 担当
- for the most part: 大部分は
- shout out: 公の場で挨拶
- to do with: 〜と関係がある
- go ahead: 進める
- bump up: 引き上げる
- go into detail: 詳細に説明する
- into detail: 詳細に説明する
- in general: 一般的に
- out of it: 意識がない
- by definition: 定義上
- look around: 見て回る
- a couple hundred: 約200
- as useful: 同じくらい役に立つ
- as well as: ~と同様に…も
- work on: 取り組む
- as time goes by: 時間の経過とともに
- run on: (会議などが予定よりも)長々と続く
- talking about: 〜について話す
- lead to: ~という結果につながる
- in on: 参加して
- for the heck of it: 何となくやる
- bad idea: 悪い考え
- to scale: 実物どおりに
- to date: 現在まで
- on to: 上へ
- go on: ~し続ける
- end in: 〜に終わる
- join in: 参加する
- forget about: 忘れる
- think of: ~としてみなす
- right back: すぐに戻ってきてね
- play around: 不倫する : 浮気する
- with it: 最新の
- compete in: 出場する
- in case of: 〜の場合には
- field: 分野
- record: 最高記録
- application: アプリケーション
- performance: 実行
- primary: 主要な : 第一の
- d: d
- product: 製品 : 商品
- tag: 鬼ごっこ
- index: 指数
- table: 表
- key: (テスト : 問題の)解答 : 解説集
- size: 大きさ : 寸法
- buffer: バッファ
- server: (コンピューターの)サーバー
- indistinct: 不明瞭な
アプリで完全な体験を
いつでもどこでも学習、文章と使い方を詳しく解説
01:03
She took a brave step forward, leaving behind her comfort zone to chase her dreams.
単語・フレーズ
- brave
adj. 勇気のある
- comfort zone
phr. コンフォートゾーン
文の解説
a brave step は名詞句で、brave は形容詞として名詞 step を修飾し、「勇敢な一歩」を意味します。
forward は副詞として step を修飾し、「前へ」を意味します。
この句全体が目的語となり、took(動詞)の「何を」に答えています——彼女は勇敢な一歩を前へ踏み出した。
アプリで完全な体験を
いつでも単語を調べて、発音・品詞・使い方をマスター
brave
US/brev/
UK/breɪv/
adj.勇敢な
v.t.勇敢に立ち向かう
A2 初級
アプリで完全な体験を
いつでもどこでもスピーキング練習、即時に発音フィードバック
Try this speaking exercise.
この文を真似して練習してみましょう。
80
0
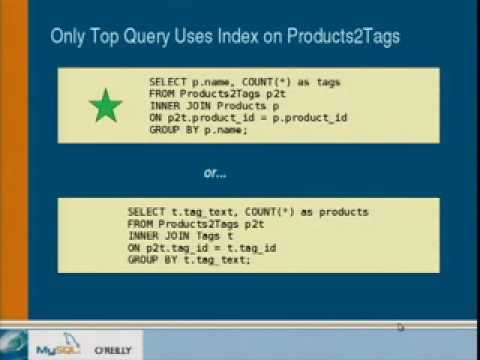
陳柏霖 が 2021 年 01 月 14 日 に投稿MySQLデータベースを驚くほど高速化するにはどうすればよいか、疑問に思ったことはありませんか?この動画では、ベンチマークからインデックスのガイドラインまで、パフォーマンスチューニングの実践的なヒントを掘り下げていきます。仕事で役立つ必須の語彙を習得し、プロのようにクエリを最適化する方法を学びましょう!
この動画をアプリで学ぼう!
VoiceTubeアプリ版なら、効果的な学習機能がもっと充実しています!